-
terraform으로 스프링부트 빠르게 배포하기 with autoscaling-groupterraform 2023. 8. 18. 03:16
이전 포스팅을 읽고 오면 좋다.
terraform으로 스프링부트 빠르게 배포하기 with ELB
https://xodns.tistory.com/136 terraform으로 스프링부트 빠르게 배포하기 with nginx https://github.com/TaeWoonJeong/terraform-spring-nginx GitHub - TaeWoonJeong/terraform-spring-nginx Contribute to TaeWoonJeong/terraform-spring-nginx developmen
xodns.tistory.com
사전 준비
이번에도 역시 사용자 2명으로 진행합니다.
1. terraform 사용자는 이전 포스팅과 같게 설정합니다.
AmazonEC2FullAccess AmazonS3FullAccess AWSCodeDeployFullAccess IAMFullAccess ElasticLoadBalancingFullAccess
2. spring build를 하고, s3에 올리고, codedeploy를 작동시키기 위한 사용자를 하나 만들어줍니다.
이전 포스팅과 동일하게 만들어줍시다.

3. state를 저장해주는 버킷을 하나 만들어줍시다.

4. build해서 나온 zip 파일을 저장해주는 버킷을 하나 만들어줍시다.

5. ALB의 액세스 로그를 저장해줄 버킷을 만들어줍니다.

버킷 권한 설정은 이전 포스팅을 보고 만들어줍시다.
6. codedeploy의 어플리케이션을 생성해줍니다.
workflow를 보면, spring-autoscaling-deploy 라고 적어줬으므로, 이렇게 만들어줍시다.
로컬에서 테라폼만 따로 실행하려면, aws cli 를 설치한다음, configure를 terraform 사용자로 해줘야 작동합니다.
스프링 설명
spring boot 어플리케이션을 하나 만들어준다.
@RestController class Controller { val uuid: String = UUID.randomUUID().toString() @GetMapping("/health") fun health() : String{ return "OK" } @GetMapping("/info") fun info() : String { return "현재 시간은 "+ LocalDateTime.now() + "이고, uuid 값 : "+uuid } }target_group이 health체크를 할 경로는 health로 했고, 실제로 로드밸런싱이 잘 되는지 확인은 info 로 들어가면 된다.
ec2 2개에 각각의 스프링이 실행될것이므로, 정상적으로 로드밸런싱이 된다면, 새로고침할 때마다 UUID값이 바뀔것이다.
테라폼 설명
1. vpc 를 만든다.
2. 만든 vpc 의 subnet을 두개 만들어준다.(ALB를 사용할 것이므로 서브넷을 최소 2개 이상 만들어야합니다.)
3. ec2가 인터넷이 가능해야하므로, 만든 vpc에 인터넷 게이트웨이를 만들어준다.
4. autoscaling-group 을 사용할 것이므로 launch template(시작 템플릿)을 만들어준다. 시작 템플릿을 만들때 subnet을 지정해줘야해서, 만든 서브넷 2개중 하나를 지정해준다.
5. launch template를 가지고 autoscaling-group을 만들어준다. 가장 최신버전의 템플릿을 사용할 것이므로
launch_template { id = var.aws_launch_template_id version = "$Latest" }이렇게 해준다. 또한 scale out, scale in 정책을 만들어준다.
6. 어떤 상황에서 scale out, scale in 을 해줄지를 정해줘야하므로, cloud watch metric alarm을 만들고, scale out, scale in 정책과 연결시켜준다.
resource "aws_cloudwatch_metric_alarm" "tw_cloudwatch_metric_scale_out_alarm" { alarm_name = "tw-ELB-request-scale_out_alarm" comparison_operator = "GreaterThanOrEqualToThreshold" evaluation_periods = 2 threshold = 1000 alarm_description = "ELB request scale out alarm" metric_name = "RequestCount" namespace = "AWS/ApplicationELB" period = 60 statistic = "Sum" dimensions = { LoadBalancer = var.aws_alb_arn_suffix TargetGroup = var.aws_target_group_arn_suffix } alarm_actions = [var.aws_scale_out_policy_arn] }이렇게 만들었는데, ALB에 요청이 1000건이 넘으면서, evaluation_periods 가 2 이고, period가 60 이므로, 60초에 1번씩 평가를 하는데, 이게 총 2번이상이 되어야 scale_out이 된다.
즉 2분동안 1000건이 넘으면, scale out 이 된다.
scale in 알람은 위와 반대로 만들었다.
순서에 상관없는 것들
security-group 생성, key-pair 생성을 해줍니다.
생성이 완료되었다면, role을 만들어주고(이전과 다른점은 ec2에서 private s3 의 spring.zip 을 처음 시작할때 다운받아와서, 실행시켜줘야하므로 AmazonS3ReadOnlyAccess를 추가해줬습니다.)
마지막으로 alb가 생성되고, target group 가 생성됩니다.
성공한다면, 최상위 main.tf에서
backend "s3" { bucket = "tw-spring-asg-tfstate" key = "terraform.tfstate" region = "ap-northeast-2" }설정이 있어서 성공한다면 state파일을 s3에 저장해줍니다.
ALB 설명

ALB에서 타겟 그룹이로 전송하는 사진 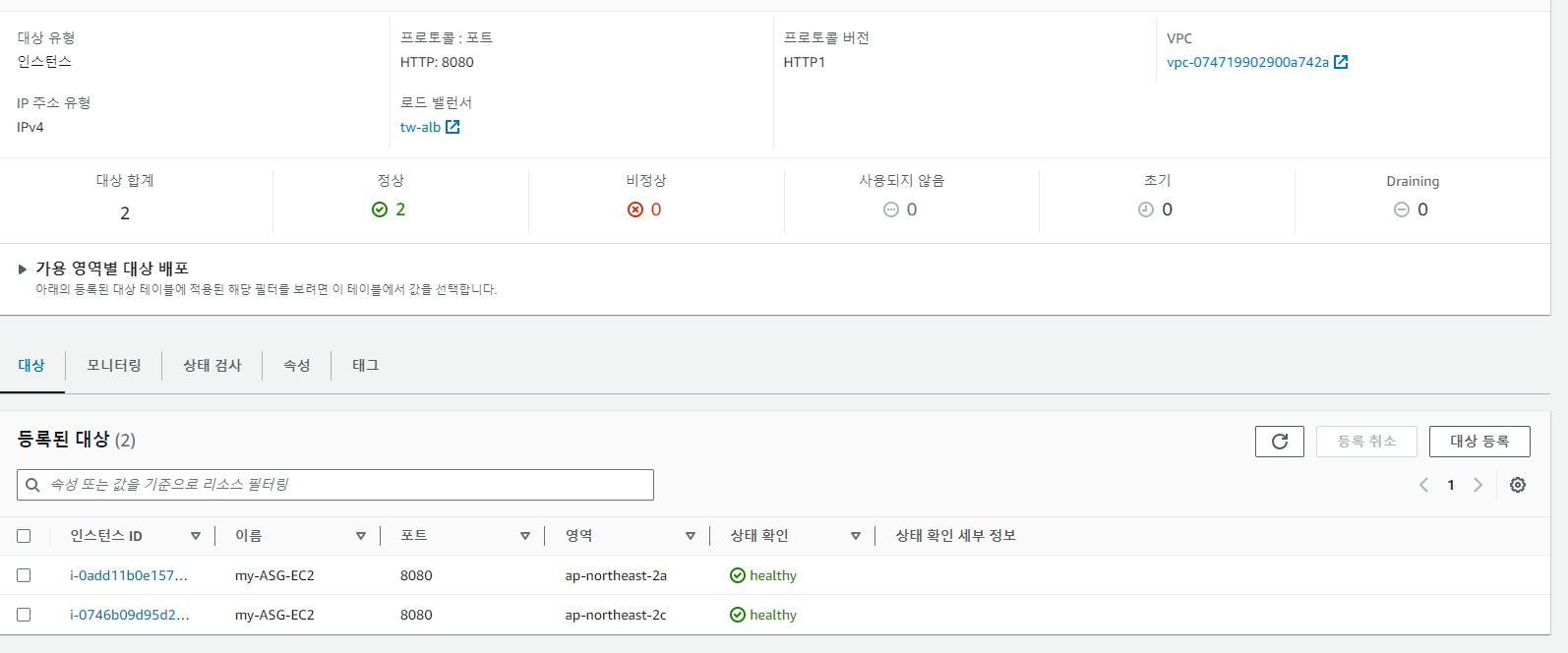
타겟그룹에서 ec2로 health check 하는 사진 ALB에서 http 요청이 온다면, target_group으로 연결해주고, target_group은 ec2의 8080포트로 보내줍니다.
resource "aws_autoscaling_group" "tw_autoscaling_group" { name = var.autoscaling_group_name vpc_zone_identifier = var.aws_subnet_ids launch_template { id = var.aws_launch_template_id version = "$Latest" } min_size = 2 max_size = 4 desired_capacity = 2 target_group_arns = [var.aws_alb_target_group_arn] health_check_grace_period = 300 health_check_type = "ELB" tag { key = "Name" value = var.ec2_name_tag_value propagate_at_launch = true } }asg에서 target_group의 arn을 연결해줍니다.
이전 포스팅과 동일하게 ALB의 access_log 설정도 했으므로, s3에 가서 로그를 볼 수도 있습니다.
github actions workflow 설명
destroy와 create-deploy 부분을 나눴습니다.
destroy는 수동트리거만 가능하게 만들었고, create-deploy는 push가 발생하면, 작동합니다.
내용은 이전 포스팅과 같습니다.
Cloud Watch를 사용한 이유

대상 추적 크기 조정인 경우 조건 변경 불가능 ASG에서 동적크기조정 정책에서, 대상 추적 크기 조정으로 하고, ALB랑 연결시킨 경우, 조건을 수정할 수가 없다. ALB에게 100건 이상이 간다면, scale out 하게 만들었는데, 3분내 라는 조건에 부합해서, scale out 은 잘 되었는데, scale in 을 하려면 15분을 기다려야해서, 분을 바꾸려고 했지만, 바꿀수 없다고 한다.
https://sweetysnail1011.tistory.com/59
[AWS EC2] 38. AutoScaling 정책
ㅇAutoScaling 정책 설정 > [EC2] - [Auto Scaling 그룹] - [정책을 적용할 AutoScaling 그룹] - [자동 조정]에서 현재 지정된 조정 정책을 확인 가능 1) 대상 추적 조정(Target Tracking Scaling) > 사용 시 AutoScaling 그룹
sweetysnail1011.tistory.com
그래서 단순조정으로 하고, cloudwatch 경보를 생성하고, scalee out 정책과 scale in 정책을 만들고 해당 경보와 연결시켰습니다.
성공 모습



로드밸런서의 DNS이름으로 접속한 모습이다.
다음으로 cloud watch 경보를 보겠다.
아직 요청을 많이 안보냈으므로, scale in 경보가 계속 켜져있다.
물론 ASG를 만들때 최소 개수가 2개이므로, 인스턴스가 줄지는 않는다.

curl로 부하를 줘보겠다.
seq 1 10000 | xargs -n1 -P10 curl -s -X GET "URL_HERE"이렇게 해서, 1번에 10개의 프로세스가 요청을 10,000건 보낸다.
총 100,000 건 요청을 보내는 것이다.
적어도 2분 넘게 요청이 계속 갈것이다.
cloud watch 그래프를 봐보자.
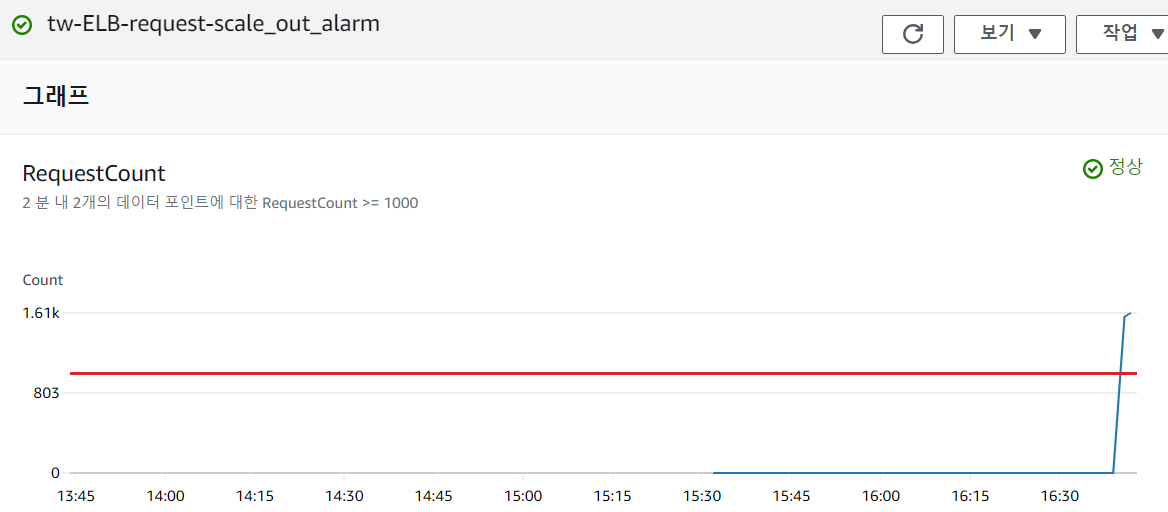
좀더 기다리면, 초록색 체크표시에서 빨간색 위험 표시로 바뀌고, ec2가 하나 늘어날 것이다.

경보 상태로 갔으니, ec2가 하나 늘어난다.

terraform 코드에서 cooldown이 90초로 지정해줘서, 90초동안은 요청이 아무리 많아도 ec2가 늘어나지 않는다.
정확히 1개만 늘리고 끄기에는 cloudwatch에 반영 속도가 조금 늦어서, 그냥 4개 다 늘어나는지 확인한다.


4개




이렇게 4개의 UUID가 다르다. 위에서 처음 2개 결과인 2755, 6295 모두 있고, 새롭게 추가된 2개의 인스턴스로도 로드밸런싱이 잘 되는 모습을 볼 수 있다.
이제 요청을 그만 보내고 조금 기다리면, 처음처럼 2개로 돌아올 것이다.
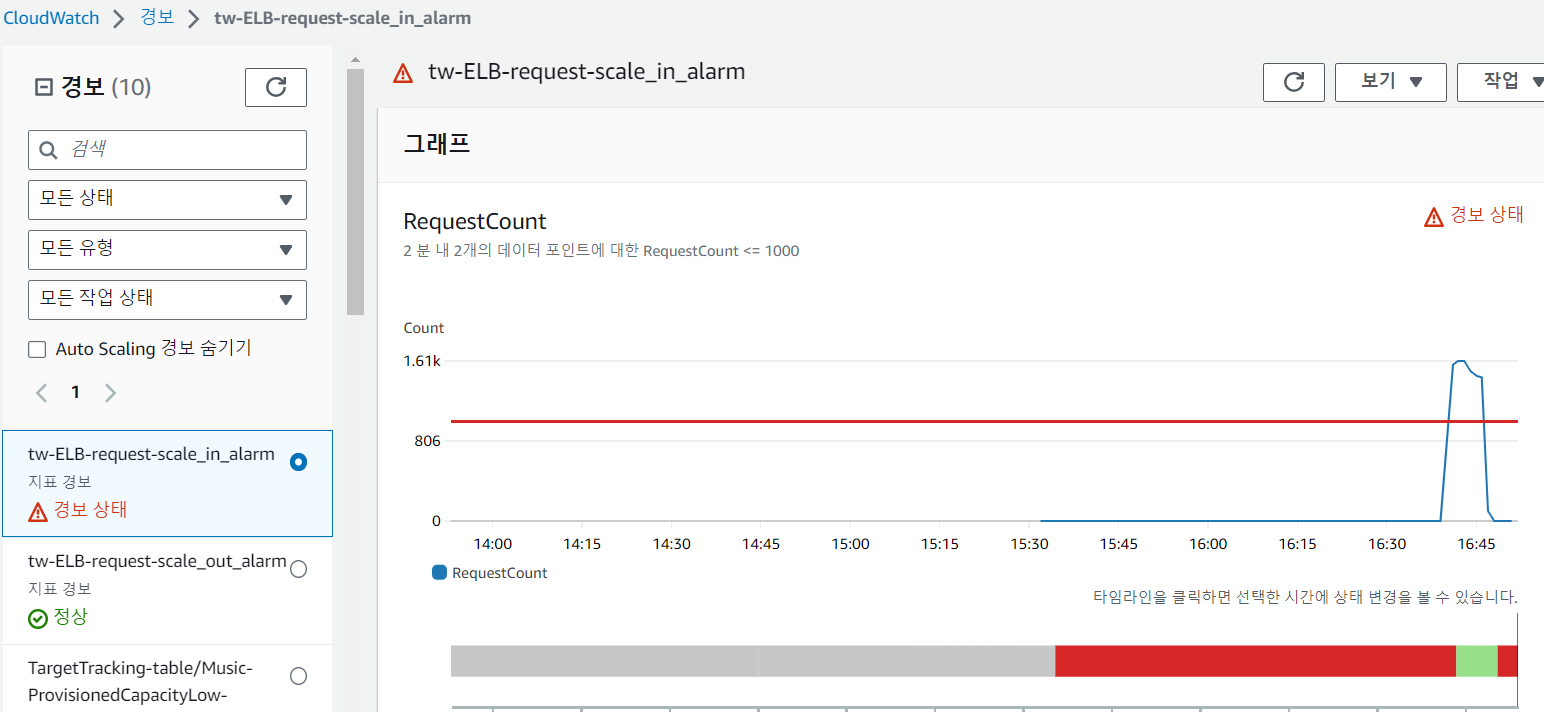
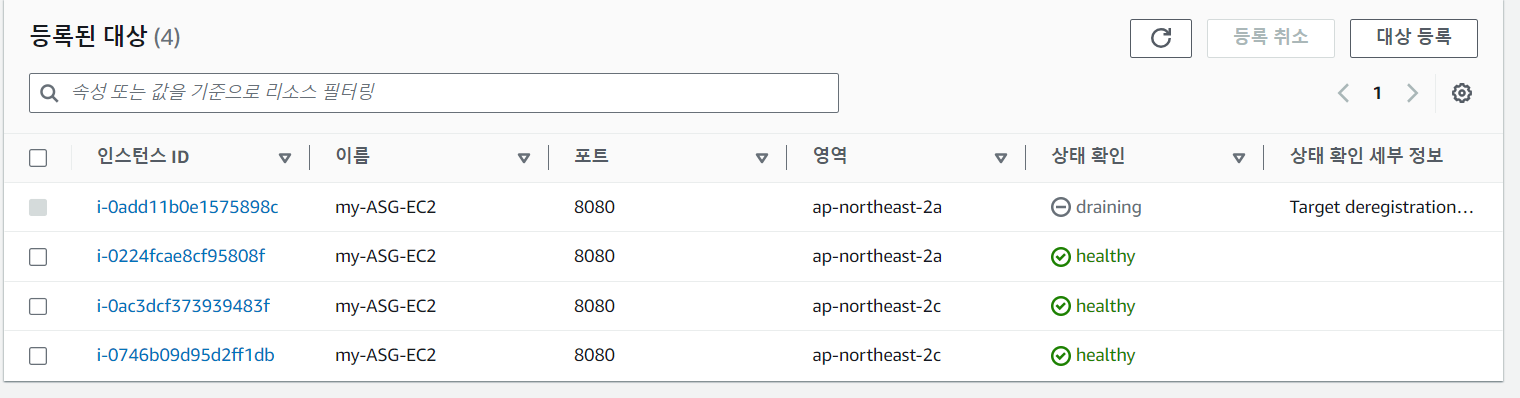

draining 하는데 시간이 좀 오래걸린다..


이제는 이렇게 2개만 나온다.

실행중이지만, target_group에서 draining 하는 중이어서 요청이 가지 않는다.


마지막으로, codedeploy가 잘 연결되는지 확인해보기 위해, 스프링 코드를 바꿔보겠다.
@GetMapping("/codedeploy") fun test() : String { return "codedeploy 작동 확인용도, 현재 시간은 "+ LocalDateTime.now() + "이고, uuid 값 : "+uuid }물론, codedeploy가 작동하면서, 기존의 jar파일을 끄기 때문에 UUID값은 변경된다.

이미 리소스가 있으므로, create에서 시간이 엄청 줄었다.



잘 작동한다.
실험이 끝났으니, github actions 에서 destroy를 눌러주면서 리소스 정리를 한다.
'terraform' 카테고리의 다른 글
terraform으로 스프링부트 빠르게 배포하기 with ELB (0) 2023.08.13 terraform으로 스프링부트 빠르게 배포하기 with nginx (0) 2023.08.13 aws 강의실 vpc 실습 terraform 으로 만들기 (0) 2023.08.10